


Autor: dr. sc. Ana Brcković Gruić
Glavni cilj ovog istraživanja bio je povezati pješčenjačke naslage, potvrđene u postojećim bušotinama, kroz prostor u kojem bušotina nema. Upravo ova korelacija između bušotina predstavlja najveći izazov u geološkoj i geofizičkoj interpretaciji. Kako rekonstruirati prostorno rasprostiranje stijena kada podatke imamo samo lokalno?
Najizravniji uvid u podzemlje daju bušotinski podaci i jezgre, koji omogućavaju precizno određivanje litološkog sastava i fizikalnih svojstava stijena. No, oni su uvijek ograničeni na vrlo uski prostor (Telford et al., 2004). Tradicionalno se zato koriste seizmički podaci kako bi ispunili praznine između bušotina (Slika 1). Interpretacija se temelji na principu superpozicije i mogućnosti lateralnog praćenja horizonata. Međutim, pretpostavka da se signali u seizmičkom zapisu mogu jednoznačno povezati s geološkim granicama često nije primjenjiva u praksi zbog šuma, promjenjive rezolucije i geološke kompleksnosti. Time pouzdano povezivanje pješčenjačkih tijela kanalnih ispuna progradacijske delte postaje vrlo teško (Vukadin i Čikeš, 2017).
Zato u priču ulazi strojno učenje, koje u posljednja dva desetljeća sve snažnije mijenja postupak interpretacije u mnogim znanstvenim područjima. Cilj nije bio zamijeniti interpretatora, nego ubrzati i unaprijediti korake koji se i danas rade pretežito ručno, poput čišćenja podataka, prepoznavanja obrazaca i predviđanja svojstava podzemlja tamo gdje mjerenja nedostaju (Banas et al., 2021; McDonald, 2021).
U ovom istraživanju korišteni su algoritmi za uklanjanje šuma iz bušotinskih podataka (IF, SVM, LOF), modeli za predviđanje karotažnih krivulja na pozicijama bez mjerenja (najbolje rezultate postigla je LSTM neuronska mreža) (Slika 2), te SOM-klasteriranje na seizmičkim podacima kako bi se odredila distribucija tipova stijena bez unaprijed zadane klasifikacije (Chaveste et al., 2023; Li i Gao, 2023 ) (Slika 3). Dodatno, razvijen je poluautomatski pristup izvlačenju seizmičkih horizonata pomoću pohlepnog algoritma lokalne optimizacije (engl. greedy algorithm), što je omogućilo preciznije definiranje geometrije rezervoarskih tijela.
Sve metode primijenjene su na području Dravskog bazena, a rezultat je prvi geološki model rasprostiranja pješčenjačkih rezervoarskih tijela u sjeverozapadnom dijelu polja Gola u potpunosti napravljen pomoću Python-a (Brcković et al., 2026) (Slika 4). Istraživanje je provedeno uz opsežne podatke i stručnu podršku INA d.d.
Ustanovljeno je da strojno učenje može biti iznimno vrijedan alat u geofizičkoj interpretaciji. Ono omogućuje brže analize, otkrivanje skrivenih uzoraka i donošenje pouzdanijih zaključaka, naravno uz stalno „budno oko“ interpretatora koje ostaje nezamjenjivo.
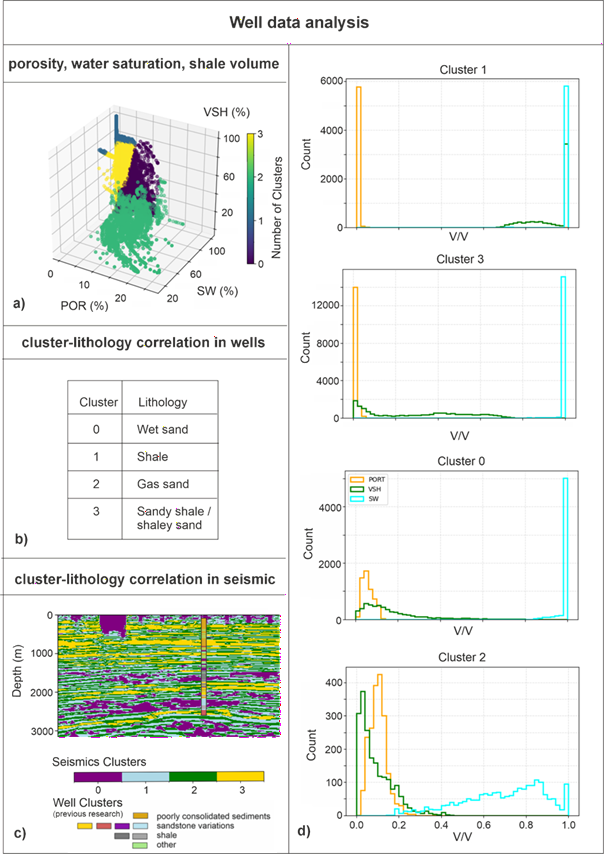
Slika 1. Korelacija klastera i litološkog sastava temelji se na: (a) poroznosti (POR), zasićenosti vodom (SW) i raspodjeli volumena šejla (VSH) u bušotinskim podacima te prikazuje grupiranje bušotinskih podataka na temelju POR-a, SW i VSH-a; (b) prikazani su različiti litološki sastavi koje se mogu odrediti iz spomenutog grupiranja; (c) slijedeći logiku da se isti litološki sastavi trebaju razlikovati na seizmičkim podacima, četiri klastera na seizmici odgovaraju grupiranju bušotina; (d) logika iza definiranja četiri klastera temelji se na POR-u, VSH-u i raspodjeli SW-a u bušotinskim podacima.
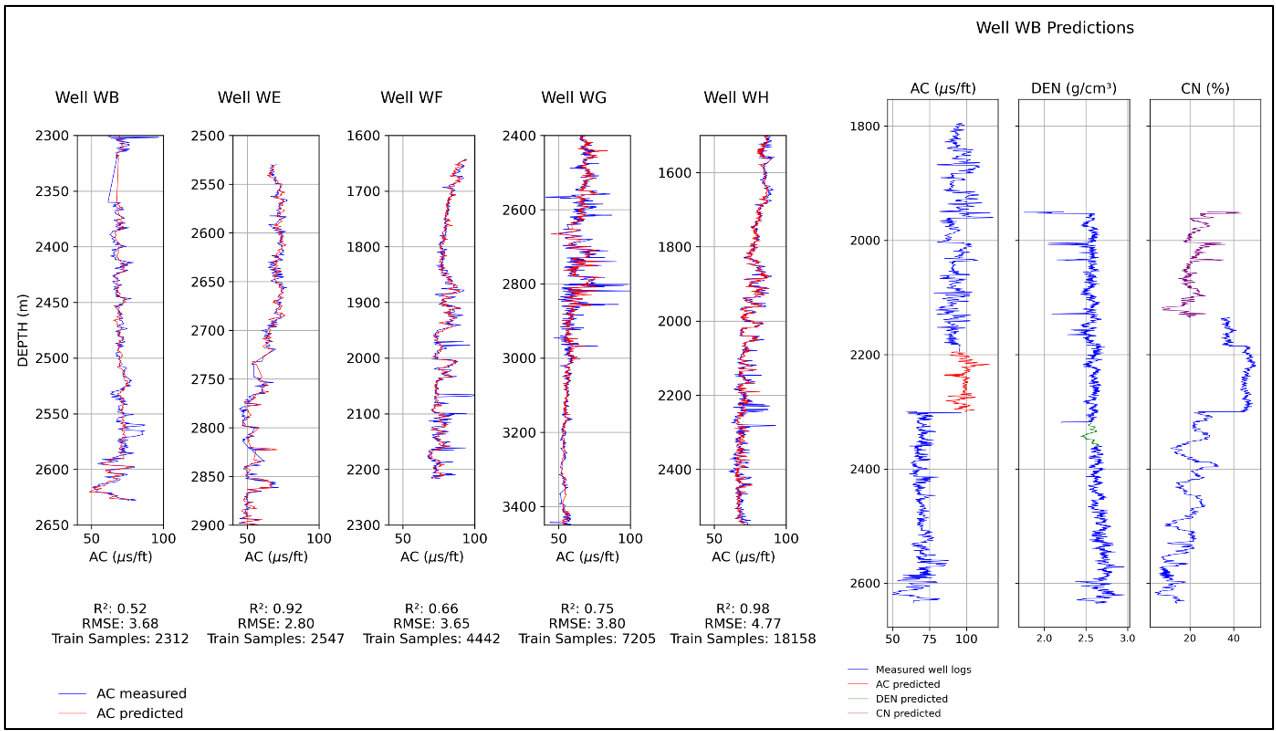
Slika 2. Prikaz predviđene vrijednosti (crveno) preko izmjerenih (plavo) na bušotinama WB, WE, WF, WG i WH, s koeficijentom determinacije (R2) i srednjom kvadratnom pogreškom (RMSE) kao metrikama (lijevo); i prikaz predviđanja zvučne karotaže (AC), karotaže gustoće (DEN) i kompenzirane neutronske karotaže (CN) s LSTM neuronskom mrežom u bušotini WB (desno).
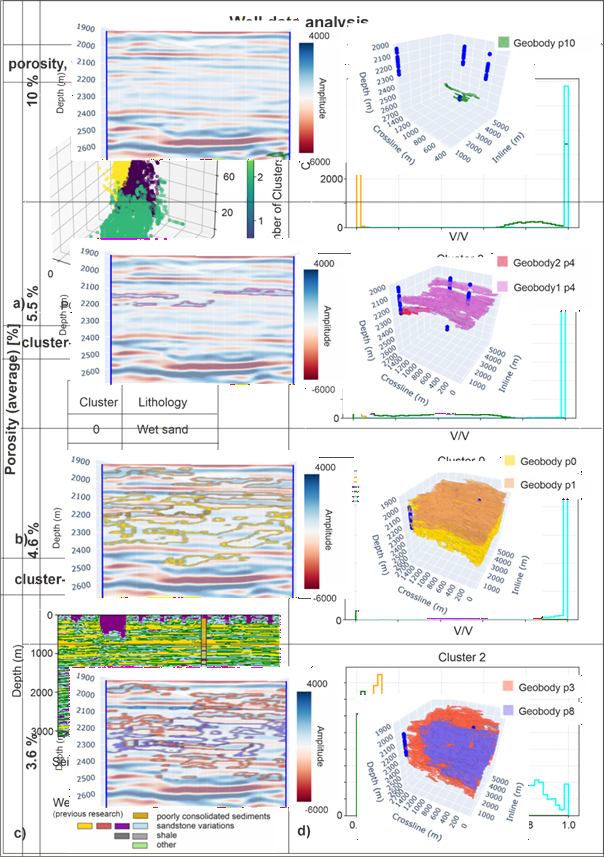
Slika 3. Korelacija tijela pješčenjaka otkrivenih SOM interpretacijom seizmičkih podataka uz validaciju i poroznostima izmjerenim u bušotinama. Vidljivo je da su prosječne poroznosti pripisane naslagama pješčenjaka općenito veće u vertikalno i lateralno manjim i ograničenijim tijelima.
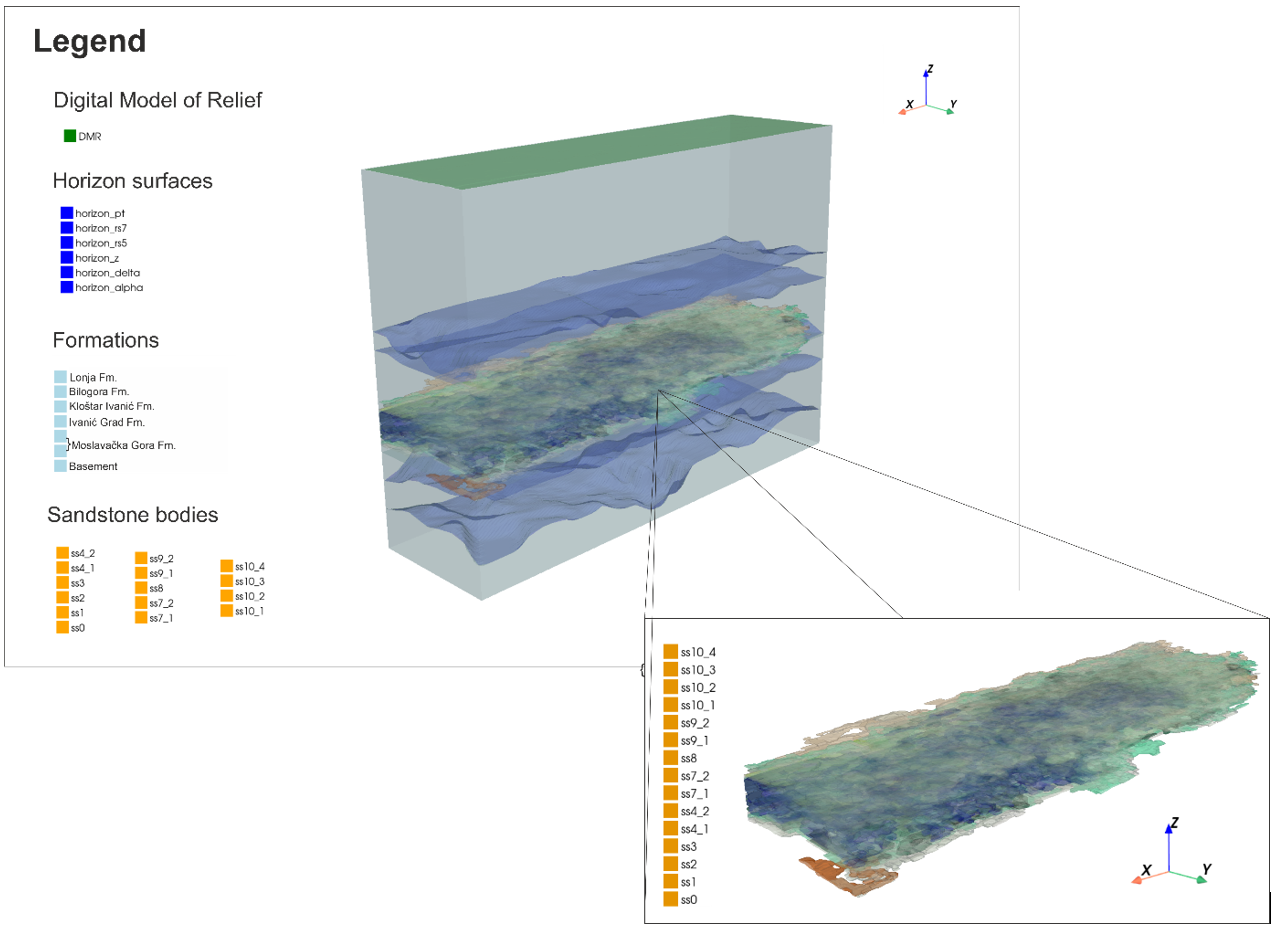
Slika 4. Geološki model polja Gola napravljen pomoću Python okvira, koji sadrži DMR, površine horizonata (automatski izdvojene pohlepnim „greedy“ algoritmom) i 14 geotijela koja predstavljaju potencijalne ležišne pješčenjake s različitim petrofizičkim svojstvima (izdvojene metodama nenadziranog učenja).
Reference
Telford, W. M., Geldart, L.P., Sheriff, R.E. (2004): Applied Geophysics, Second Edition. Cambridge University Press. Cambridge
Vukadin, D., & Čikeš, K. (2017). Using seismic inversion and seismic stratigraphy as a combined tool for understanding a small scale turbidite systems: Gola field, Pannonian basin, Croatia. https://www.researchgate.net/publication/341569134
Banas, R., McDonald, A., & Perkins, T. (2021, May 17). NOVEL METHODOLOGY FOR AUTOMATION OF BAD WELL LOG DATA IDENTIFICATION AND REPAIR. SPWLA 62nd Annual Online Symposium Transactions. https://doi.org/10.30632/SPWLA-2021-0070
McDonald, A. (2021). Data Quality Considerations for Petrophysical Machine-Learning Models. In Petrophysics (Vol. 62, Number 6, pp. 585–613). Society of Petroleum Engineers (SPE). https://doi.org/10.30632/PJV62N6-2021a1
Chaveste, Alvaro, Roden, Rocky R., and Smith, Tom. 2023. Machine Learning-Based Method Provides Economic Option To Seismic Inversions Conventional Inversion. The American Oil & Gas Reporter, Volume 66, No. 11. 43-49.
Li, J., & Gao, G. (2023). Digital construction of geophysical well logging curves using the LSTM deep-learning network. Frontiers in Earth Science, 10. https://doi.org/10.3389/feart.2022.1041807
Brcković, A., Vukadin, D., Medved, I., & Orešković, J. (2026). Reconstructing the Distribution of Turbiditic Gas Sandstones in the SW Pannonian Basin Using Machine Learning Methods. Geophysical Prospecting, 74(2). https://doi.org/10.1111/1365-2478.70146